9.7 KiB
Les architectures distribuées
William Petit - S.C.O.P. Cadoles
Les architectures distribuées (1)
Qu'est ce qu'une application distribuée ?
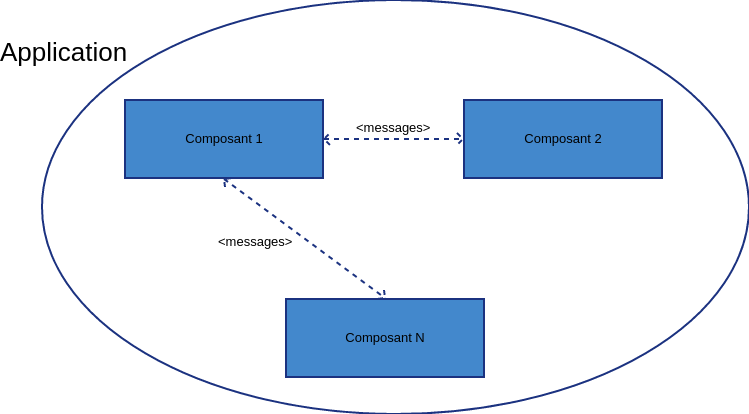
Une application distribuée est une application informatique constituée de composants indépendants (i.e. processus distincts et sans partage de mémoire) communiquant via des messages.
Les architectures distribuées (2)
Exemples d'applications distribuées
- Sites/applications Web
- Jeux en ligne multijoueurs
- Gestionnaire de version de code source (SVN, Git, etc...)
- Serveurs de courriel
Les différents modèles d'architectures distribuées
Modèle 2 tiers (ou client/serveur)
Modèle 3 tiers
Modèle N tiers
Le modèle 2 tiers (ou "client/serveur")
Définitions
Les différentes topologies
Communication client/serveur
Répartition des traitements
Le middleware
Exercice : Implémentation d'une calculatrice par TCP/IP
Définitions
- Client Processus demandant l’exécution d’une opération à un autre processus par envoi de message contenant le descriptif de l’opération à exécuter et attendant la réponse de cette opération par un message en retour.
- Serveur processus accomplissant une opération sur demande d’un client, et lui transmettant le résultat.
- Requête message transmis par un client à un serveur décrivant l’opération à exécuter pour le compte du client.
- Réponse message transmis par un serveur à un client suite à l’exécution d’une opération, contenant le résultat de l’opération.
Les différentes topologies
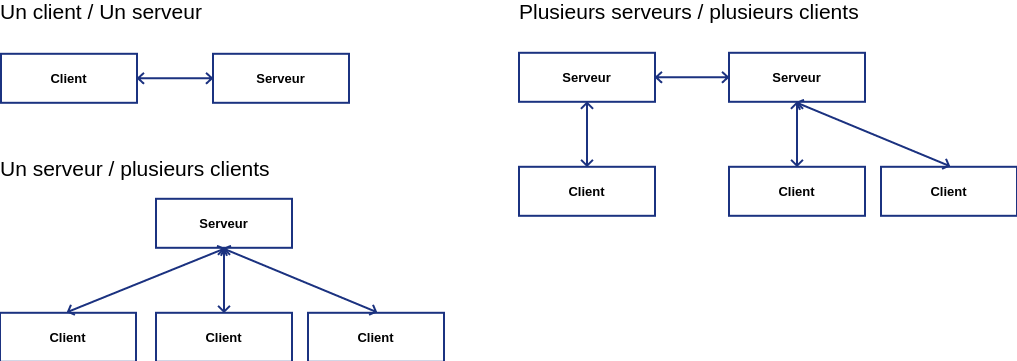
Communication client/serveur (3)
Protocole de communication
Une application distribuée étant fondamentalement un environnement hétérogène (composants indépendants). Il est donc nécessaire de définir un "langage commun" (ou "protocole") pour que les composants puissent communiquer entre eux.
La spécification de régles de sérialisation et désérialisation des structures de données échangées (messages) est souvent à la base de la définition des protocoles d'échange.
Exemples de formats de sérialisation sur Wikipédia
Communication client/serveur (2)
Modes de communication

Communication client/serveur (3)
Différences entre les deux modes
Synchrone
- Les messages sont émis aussitôt
- Bloquant
- Pas de file d'attente de traitement
Asynchrone
- Nécessite une file d'attente de traitement
- Non bloquant
- Favorise le multitâche/la montée en charge
Répartition des traitements (1)
Couches de traitement
La conception d'une application distribuée nécessite d'établir une répartition de la responsabilité des traitements sur les différents composants. On peut catégoriser ces traitements par "couche":
- Couche de présentation rendu des interfaces textuelle ou graphique destinée à l'utilisateur de l'application, gestion des interactions, validation des entrées...
- Couche métier/logique traitement appliqués sur les modèles de données de l'application, validation des données...
- Couche de données Persistance et accès aux données de l'application
Répartition des traitements (2)
Classification des architectures 2 tiers (Gartner Group)

Le middleware (1)
Aussi appelé "intergiciel" ou "intersticiel" en français.
Rôle
- Ensemble de services logiciels construits au dessus d’un protocole de transport afin de permettre l’échange de requêtes et des réponses associées entre client et serveur de manière transparente.
- Les services du middleware sont un ensemble de logiciels répartis qui existe entre l’application, l’OS et les services réseaux sur un nœud du réseau.
Le middleware (2)
Fonctions
- Procédure d’établissement de connexion
- Exécution des requêtes
- Récupération des résultats
- Procédure de fermeture de connexion
- Gestion des accès concurrents
- Sécurité et intégrité
- Monitoring
- Terminaison des processus
- Mise en cache des résultats
- Mise en cache des requêtes
Le middleware (3)
Différentes techniques
- Échange de messages, ou MOM - Message Oriented Middleware. Exemple: AMQP, NATS
- Appel de procédures distantes, ou RPC. Exemple: JSON-RPC2, XML-RPC, SOAP.
- Manipulation d'objets Exemple: REST, DCOMM, CORBA, RMI
Le middleware (4)
Exemple: RPC
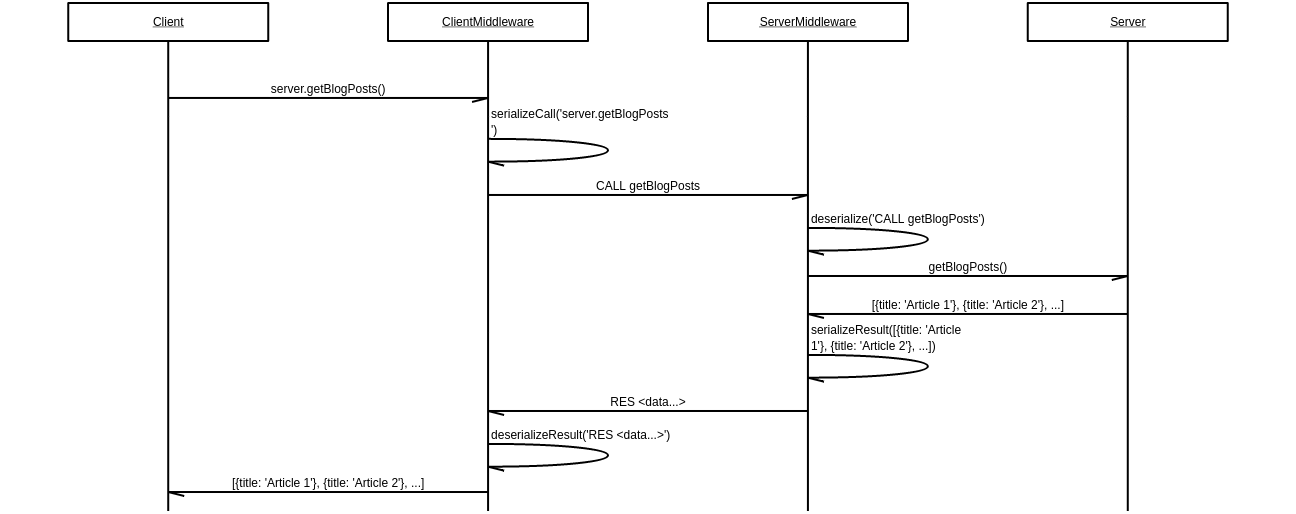
Exercice
Implémentation d'une calculatrice à état distribuée en NodeJS
L'architecture 3 tiers
Généralités
Transactions
Sécurité
Généralités (1)
Principe
L'architecture 3 tiers est le modèle d'architecture applicative le plus utilisé aujourd'hui dans la conception d'application. Il propose de découper l'application en 3 couches aux rôles distincts:
- Couche présentation
- Couche logique/métier
- Couche persistence/données
Généralités (2)
Exemple: Application LAMP (Linux, Apache, PHP, MySQL)

Transactions (1)
Qu'est ce qu'une transaction ?
Une transaction est une série d'opérations appliquées sur un corpus de données respectant les caractéristiques suivantes:
- Atomicité
- Cohérence
- Isolation
- Durable
Transactions (2)
Atomicité
La série d'opérations est indivisible.
Exemple
Soit une transaction comportant 3 opérations arithmétiques sur la variable ACC.
| Opération | État | Description |
|---|---|---|
| -- | ACC = 0 |
État initial |
ACC = ACC + 1 |
ACC = 1 |
Application de l'opération A |
ACC = ACC - 5 |
ACC = -4 |
Application de l'opération B |
ACC = ACC / 0 |
ACC = 0 |
Application de l'opération C. La division par 0 provoque une erreur. Retour à l'état initial. |
Transactions (3)
Cohérence
L'état du corpus de données à la fin de l'exécution de la transaction doit être cohérent (sans pour autant que le résultat de chaque opération pris distinctement soit cohérent).
Transactions (4)
Isolation
Lorsque deux transactions A et B sont exécutées en même temps, les modifications effectuées par A ne sont ni visibles par B, ni modifiables par B tant que la transaction A n'est pas terminée et validée.
Transactions (5)
Durable
Une fois validé, l'état du corpus de données doit être permanent, et aucun incident technique (exemple: crash) ne doit pouvoir engendrer une annulation des opérations effectuées durant la transaction.
Sécurité (1)
Objectifs
- Maintenir l'intégrité des données
- S'assurer du niveaux d'authentification et d'autorisation
- Maintenir la disponibilité des services
- Assurer la traçabilité des échanges
- Éviter la fuite d'informations
Sécurité (2)
Modélisation de menace
- Identification des dépendances externes. Exemple: serveur GNU/Linux, base de données
- Identification des points d'entrées Exemple: formulaire de contact, port de la base de données
- Identification des assets Exemple: Comptes utilisateurs de l'application, données personnelles, droits d'accès
- Identification des niveaux de confiance Exemple: Utilisateur anonyme, administrateur
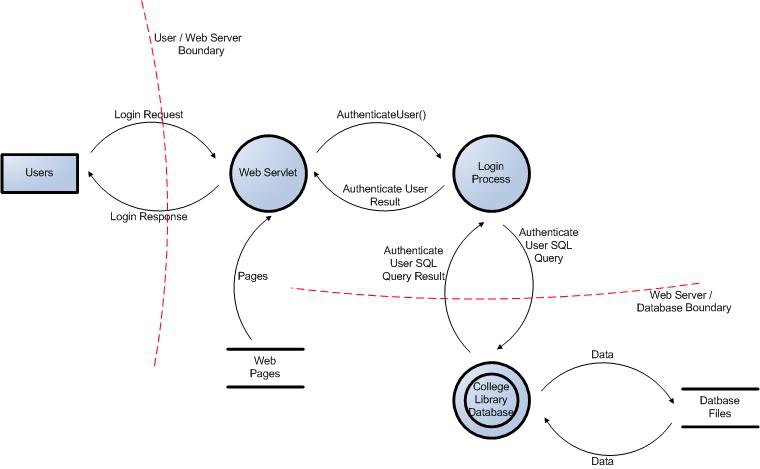
Sécurité (3)
Identification des flux de données
Modèle N tiers
Architecture orientée services (ou SOA)
Architecture orientée microservices
Exercice
Architecture orientée services (1)
Notion de "service"
Un service est un composant d'une application distribuée répondant aux caractéristiques suivantes:
- Il a pour responsabilité un domaine métier identifié (ex: gestion du paiement par carte).
- Il est autonome.
- C'est une "boite noire" pour ses utilisateurs.
- Il peut être lui même un aggrégat de plusieurs autres sous services.
Architecture orientée services (2)
Exemple
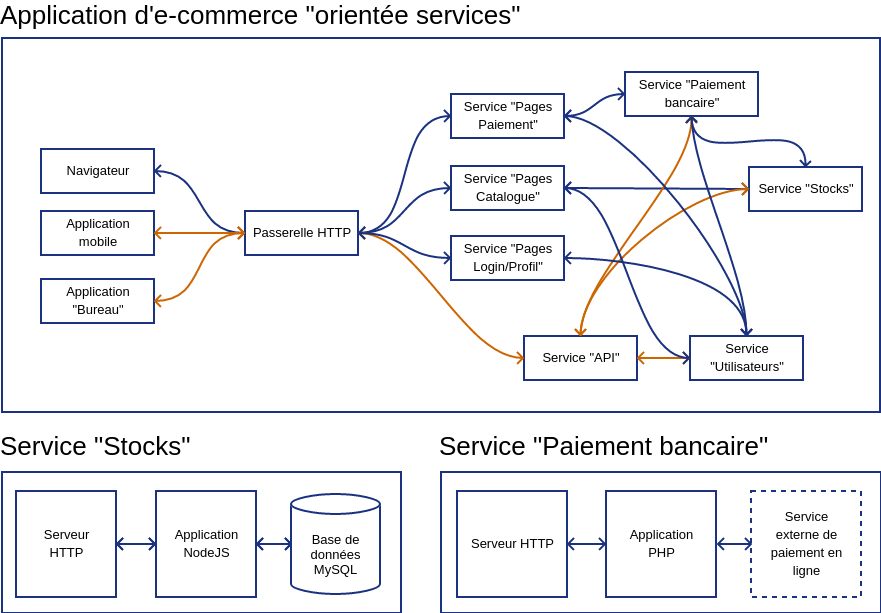
Architecture orientée services (3)
Piliers
- La plus-value métier prévaut sur la technique.
- L'interopérabilité des services doit être considérée comme une des pierres angulaires de la conception.
- La flexibilité de l'architecture doit être privilégiée à l'optimisation.
Architecture orientée microservices (1)
Différence avec le SOA
L'architecture orientée microservices est une variante du modèle plus général de la SOA.
Elle peut se résumer à la philosophie Unix "Faire une seule chose et le faire bien".
Architecture orientée microservices (2)
Piliers
- Chaque service remplit une fonction unique.
- La culture de l'automatisation du processus de développement devrait être adoptée au maximum par les équipes (mise en place de tests unitaires et fonctionnels, intégration et déploiement continu).
- L'application devrait prendre en compte et gérer l'échec d'un de ses composants.
- Chaque service est élastique, résilient, composable, minimaliste et complet.